
Learn about the practical application of Domain-Driven Design (DDD) and find out how to create clear, flexible code that supports your business at every stage.
For years, I wrote code that worked, but never explained why it worked. It performed tasks, but didn’t convey the business logic behind them. Everything changed when I discovered Domain-Driven Design. With DDD, I began building systems that not only get the job done, but also tell a story—one that’s clear to both developers and business professionals.
In this article, I will show you how the DDD approach can help you create code that is more transparent, flexible, and “alive.” Code that not only works but also makes sense.
Domain-Driven Design: Where Developers and Business Speak the Same Language
Imagine a project where developers and business people truly understand each other. Domain-Driven Design (DDD) is an approach to software development that makes this possible - it builds a bridge between the technical and business worlds.
In DDD, developers collaborate with domain experts to create a shared domain model - a consistent view of the problem that can be directly translated into code. Instead of guessing what business representatives meant, the technical team works side by side with people who know the realities of the industry.
The key element is ubiquitous language – a common language based on domain concepts. If we say “basket,” it means exactly the same thing in conversation, documentation, and code. This helps us avoid misunderstandings and build systems that truly reflect how the company operates.
DDD is not just a technique - it is a way of thinking that improves communication, increases understanding of business problems, and leads to more accurate, flexible solutions.
Where should you start?
From Click to Delivery: Designing E-Commerce Payment Systems with Domain-Driven Design
Let's now take a look at how the Domain-Driven Design approach works in practice using the example of the payment process in an online store. This is a classic scenario in which good cooperation between the technical team and the domain expert is crucial.
Imagine that you are building an e-commerce system. The customer adds products to their cart and clicks “Pay.” At this point, a whole chain of domain events is triggered. The system verifies the order, calculates the final amount, and then forwards it to the Payments module, which initiates the transaction.
Once the payment is confirmed, the next part of the system kicks in—the Warehouse module. It receives a signal to fulfill the order, employees complete the package, and the customer receives a purchase confirmation and estimated delivery date.
In this article, we will focus exclusively on the store domain, and more specifically on how to describe the responsibilities of individual system components from a business perspective. We assume that we have already agreed on a common process model with a domain expert, e.g., in the form of a flowchart. This is our contract, which will be the basis for further design.
Instead of delving into technical details right away, we will treat the system as a company with departments (i.e., modules) that work together to fulfill an order. Most importantly, everyone (developers and business experts) understands this model in the same way because it is based on a common domain language.
What Is a Domain Service in Domain-Driven Design?
A domain service is an element of the domain model that is responsible for implementing business logic not directly related to any specific entity. Its main task is to reflect real business scenarios in the code.
When I create a domain service, I always start with an established contract with a domain expert, e.g., a flowchart or process description. I use exactly the same vocabulary that appears in conversations with the business. Thanks to this, each stage of the process has its clear and consistent representation in the code, and the model remains consistent with the domain language (ubiquitous language).
I usually sketch the entire process at once, defining all the necessary classes and methods, but without implementing the technical details. Why? Because business logic and domain language should shape the structure of the code, not the other way around.
A good domain service, like the entire domain model, should be free of technological dependencies. It should work independently of the framework, database, or technical infrastructure. The implementation of a business algorithm should not require the configuration of controllers, repositories, or application layers.
This approach has a huge advantage during prototyping: you can quickly test and verify your model, easily change it, and discuss the results with a domain expert. This allows you to iteratively develop a system that truly reflects the rules governing your domain.
Key Elements of Domain-Driven Design One Should Know
Working with Domain-Driven Design is not about “implementing DDD” at all costs, but about using its tools wisely when they really help. My projects often feature certain recurring elements – patterns that work well in organizing complex business logic and facilitate communication with domain experts.
Here are the ones I use most often:
- Aggregates, aggregate factories, and repositories – such as ShoppingCart, a layer that gives objectivity to classic entities.
- Value Objects – immutable objects such as ClientID, Item, or Price, which create enriched data structures.
- Facade services – EventBus or PaymentService, which hide the complexity of external systems.
- Policies – FeePolicy or PromoPolicy, which encapsulate business rules.
Let's now move on to discussing each of them.
Aggregate in DDD: What Exactly Is It?
An aggregate is an object that you can identify, has its own state, and can be changed. The default assumption that any object whose internal state we can influence is an aggregate greatly facilitates an intuitive approach to this pattern. In other words, it is a tool for imposing objectivity on a relational data model represented by entities.
Let's take something you know from everyday life – a shopping cart. You can create it, add products to it, and eventually pay for it. Your cart contains products and may include promotions and additional fees.
Did you notice that we just described a complex object with its behaviors? That's the essence of an aggregate! You don't ask the shopping cart, “Give me a list of products so I can change it” — instead, you say, “Add this product” or “Remove that one.”
How Is an Aggregate Constructed?
An aggregate consists of entities, which are its constituent parts. These entities store data that needs to be saved in the database. They are like the skeleton of an aggregate – they provide structure, but do not have any business behavior themselves.
Why not put all the data directly in the aggregate (make the aggregate an entity at the same time)? This separation gives you more flexibility. You can use entities independently, for example in database queries. Additionally, you separate getters and setters from business logic.
An important rule: an aggregate does not share its internal entities. It communicates with the world through Value Objects. It's like in a store. You don't let others rummage through the warehouse, you just give them a specific item from the shelf.
Practical Rules for Working with Aggregates
If you are working with an object whose state you can change, you are dealing with an aggregate. This is a classic OOP object. Instead of traditional getters and setters, it contains methods that reflect its business behavior.
Do not save aggregates directly to the database. Always use a dedicated repository. Aggregates are not only data structures, but above all behaviors. Some of them require prior initialization.
Create aggregates through dedicated factories. Think of it as manufacturing a car – you don't assemble it manually from parts, you order it from a factory that knows how to do it correctly.
An aggregate should contain the business logic of its domain. If you have an aggregate called `Dog`, the method `eat(sausage)` should be part of it. This is natural and intuitive – a dog eats a sausage, rather than `dog.getStomach().setFood(sausage)` being applied to it.
Benefits of Using Aggregates
Using aggregates makes your code more understandable. Each aggregate has clearly defined responsibilities and boundaries. It is easier to ensure consistency of data and business behavior.
Aggregates also help you manage complexity. You divide large systems into specialized objects with clearly defined boundaries. It's like organizing a company into departments—each has its own specialization and communication protocols.
How Does an Aggregate Repository Work?
The aggregate repository acts as an intermediary between your domain model and the database. It translates raw data into useful business objects... And vice versa – it converts your objects back into data. In the simplest cases, the repository only wraps the entity in an aggregate object, while in more complex cases it can inject, for example, a dictionary service and other services.
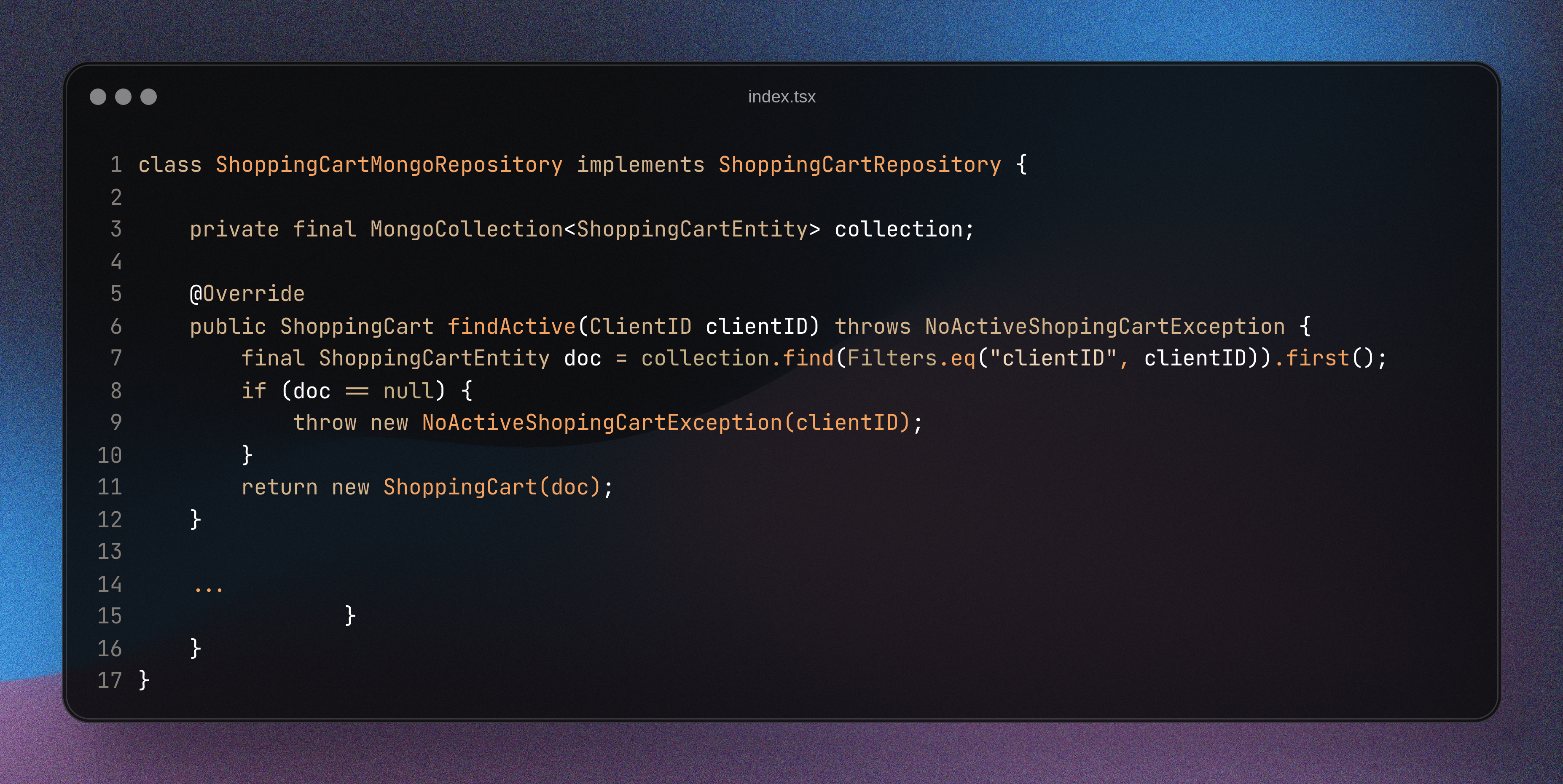
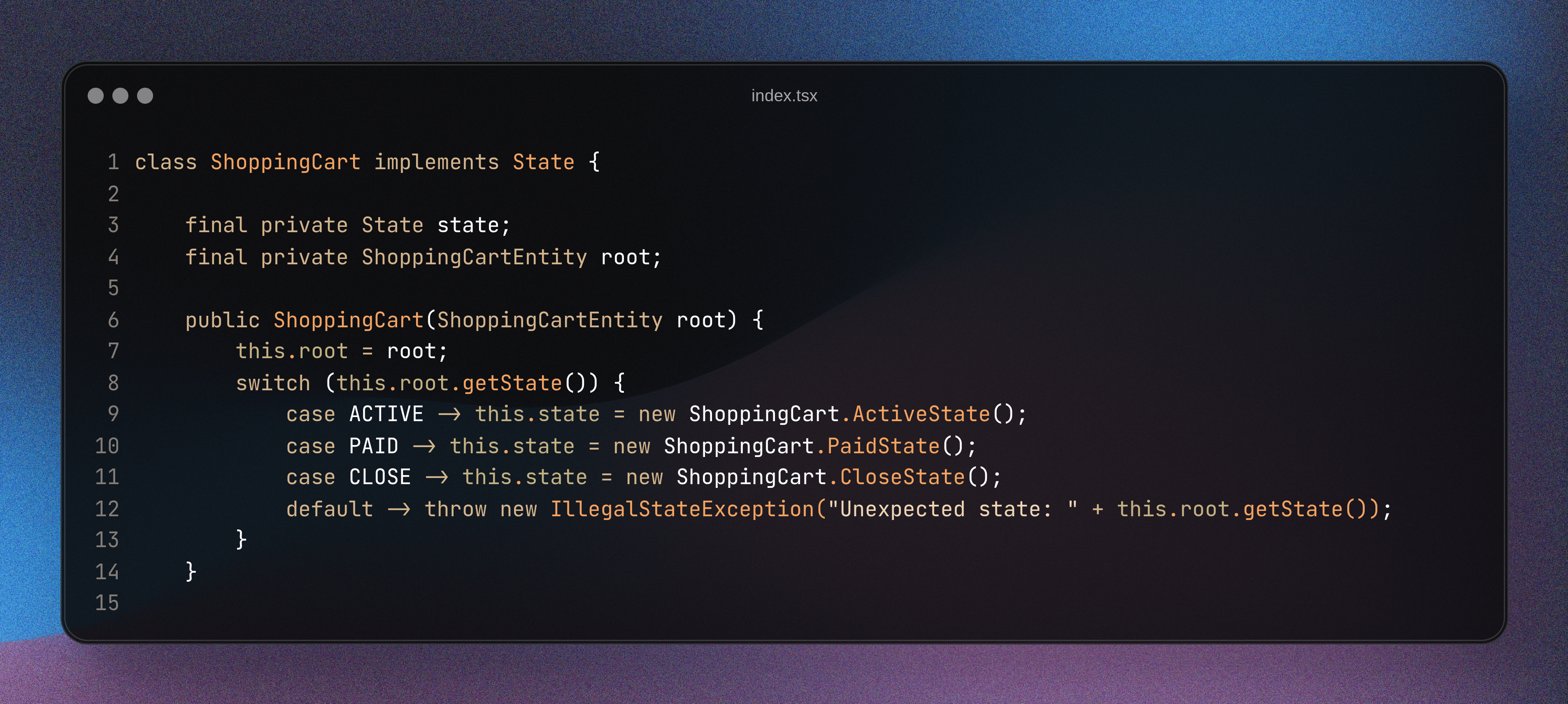
One of the biggest advantages of repositories is their technological flexibility. You can set up a repository for any data storage technology. When prototyping, I often run the model from the “main” function and use a regular file as a repository. It doesn't matter if you use MongoDB, PostgreSQL, or text files. As long as the repository correctly initializes the aggregate, you can freely change the database or CRUD service.
Think of the repository as a universal adapter—you connect it to any data source, and your model works without change.
In my approach, I use multiple writes to the repository after each change in the object's state. At the domain service level, I don't use transactions, which is consistent with the principles of microservice architecture. In such an environment, transactions can cause problems, especially when communicating with other services. However, this does not preclude the use of transactions within the aggregate at the repository level.
Wouldn't it be better for your business model to be independent of the infrastructure and framework? DDD is primarily a way to secure domain knowledge. The basic functions of a programming language are usually sufficient to describe a business model. It's like building with Lego blocks – simple elements, but unlimited possibilities.
This approach allows me to quickly prototype and verify the business model. My repository does not have to be database-driven—it can be implemented as a file or an external API. I can test the entire process even from the main function. It's like test driving a car before buying it—you check if the model works before investing in the entire infrastructure.
Remember that there are no hard and fast rules about what should be included in the aggregate. The model should reflect the nature of the domain as best as possible, but without exaggeration. If something becomes too complicated, it is worth re-analyzing it. It is worth experimenting with different approaches and finding the one that best suits your project.
Aggregate Factories: Why They Matter
Imagine a generator factory as a specialized assembly station. You assemble a complex product there, but you don't worry about storing it. That's a completely different task. Similarly, in code, it's worth separating the creation of an object from its storage and retrieval.
Creating objects often requires more business logic than saving them. Do you check the validity of data before creating a user account? That's the role of the factory. It handles data validation and retrieving information from external sources.

Have you noticed how simple implementation can be? The factory handles the creation logic, while the repository focuses solely on data storage.
Value Objects: When Simple Types Are Not Enough
Have you ever wondered why it is worth wrapping basic types in dedicated classes? Let's look at some practical examples that will change your approach to domain modeling.
There are no major issues with the BigDecimal class in Java. It is a solid tool (despite a few pitfalls that are worth knowing before a job interview). So why bother creating a Price class?
The first reason is the domain language. Imagine talking to a business expert about your code. A class named “Price” will be much more understandable to them than the technical “BigDecimal.”
Value Object gives you the ability to create dedicated factory methods. I prefer the name “of” for such methods – similar to the Google Guava library. Thanks to them, you gain the perfect place for input data validation.
In the Price class, you can immediately ensure the correct number of decimal places. You can also add currency codes and other business details. Everything happens in one controlled place.
In this case, instead of ready-made code, I will use an example of use.
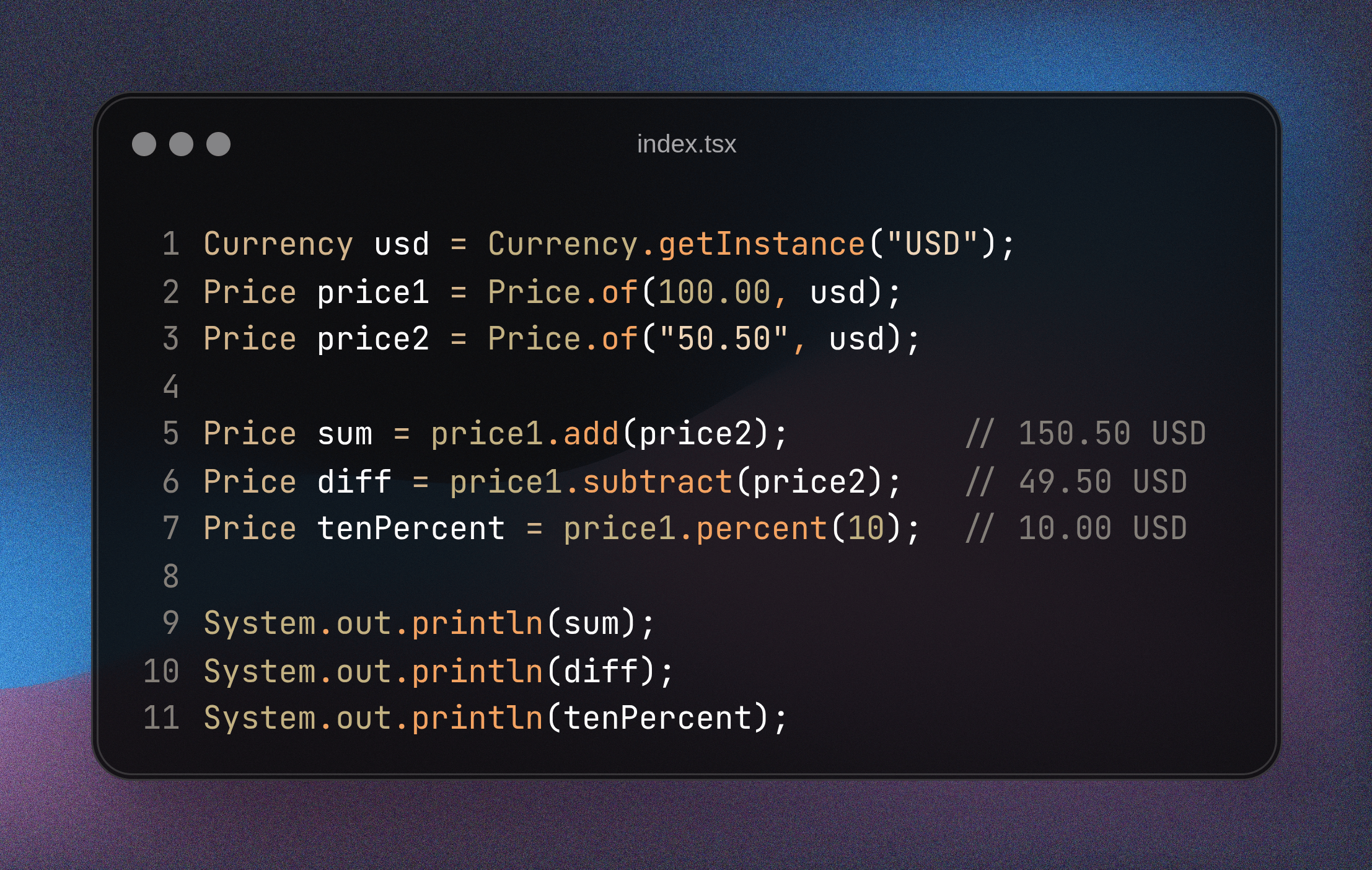
Value Object: A Practical Example Using a Bank Account Number
Think about a bank account number. You can store it as a regular String. But what do you gain by creating a Value Object called IBANNumber?
First of all, the code becomes more readable. Additionally, you can create different initialization variants:
- `IBANNumber.of(String countryCode, String number)`
- `IBANNumber.of(String ibanNo)`
You can add a method to such a class that returns information about the bank. You can also attach a function that formats the number for presentation. Sounds better than a regular String, right?
Best Practices for Designing Value Objects
A Value Object should always be immutable. When you add Price to Price, you create a third, new object – just like when you add numbers. It is a full-fledged object in the OOP paradigm. It contains business methods related to the operations it represents. It's like a little expert in its field. Static factory methods significantly improve code readability. Instead of long constructors with many parameters, you offer specialized, clearly named entry points.
Why Value Objects Are Worth It
The main argument is code readability. Your code starts speaking the language of business, not technology. All operations related to a given concept are enclosed in a single class. And again, the analogy with Lego comes to mind. A Value Object is a specialized block that we can use in many constructions.
Have you noticed how Value Objects can simplify your code? Maybe it's time to look around your own projects and find places where simple types are just begging to be replaced with full-fledged domain objects?
Facades in Architecture: Protecting Your Business Domain
Have you ever wondered how to effectively separate business logic from the rest of your application? The facade pattern can be your weapon. It acts as a security guard for your domain – it only lets in invited guests and makes sure that no one violates internal rules.
Facades create a flexible protective layer around your domain. Thanks to them, the model of one domain does not penetrate into another. It's like building a drawbridge around a castle – you control what comes in and what goes out.
Unfortunately, every strategy has its price. You have to separate transport classes (part of the facade interface) from the actual domain objects. How to deal with this challenge?
I use a simple rule: every Value Object can be part of the facade. Aggregates, on the other hand, remain inside the domain.
However, avoid excessive rigour. Rewriting and transforming large, nested transport objects (DTOs) into Value Objects would be a waste of time. Sometimes pragmatism wins over idealism.
The Two Faces of a Facade
Facades have two uses. They can serve as:
- An interface to your own domain
- An interface to an external domain that you use
Imagine a banking domain responsible for transfers and card operations. You can wrap it with a “BankFacade” facade. But what if your shopping domain only needs to initiate payments?
In this case, create an additional facade service in the purchasing domain - “PaymentFacade.” It will be a translator between the world of banking and purchasing. It's like hiring a specialist who knows both languages and simplifies communication.
Let's consider EventBus. If you want to inform the system about a completed purchase. Technically, you can use Kafka or JMS. However, in terms of domains, you present it as an “Event Bus.”
It is easier for a domain expert to understand the concept of an Event Bus than the implementation details of Kafka. From your perspective, you are buying yourself time to choose the right technology and also the option to change it in the future.
Facades fulfill two key roles:
- They simplify the complexity of your domain for the outside world.
- They translate external domains into a language that your system understands.
How do you use facades in your architecture? Maybe you use other patterns to separate domains? Share your experiences!
When “It Depends” Turns into Code: Unlocking Domain Policy Power
Have you ever heard “it depends” when discussing requirements? This answer is not an obstacle—it's a signal to take action! You've just discovered the perfect place to apply domain policy.
Domain policy is the equivalent of a strategy pattern translated into domain language. Think of it as a set of decision rules that you can swap out like cassettes in an old tape player. Each cassette plays a different tune, but fits into the same player.
When you encounter a “it depends” situation, ask yourself two simple questions: What does the decision depend on? What is the effect? The answers will help you define the policy interface.
How to Embed Policies into Your Code
Start by defining an interface that describes the decision. Consider what parameters influence the decision and what the outcome is. Treat it like a contract that specifies the input and the expected result. Then create specific implementations for different scenarios.
Did you know that you can deliver policy in many ways? You can pass it directly, generate it in a domain service, make it part of an aggregate, or expose it through an external service facade.
A policy is not just a part of a project—it is living documentation. It clearly shows what decisions you make in the system, when you apply them, and what influences them. This helps new team members understand the business logic more quickly.
Do you already use domain policies in your projects? Or maybe this will inspire you to review your code and find places where “it depends” could be transformed into an elegant, interchangeable decision-making mechanism?
The Two Faces of Errors in IT Systems: Managing Failures in the Spirit of DDD
Have you ever wondered how many things could go wrong in your system?
In the world of DDD, error management is not only a technical issue, but above all a business one. It is almost impossible to predict every possible failure. Instead, it is worth focusing on how the system should behave when a problem arises.
From the perspective of the domain model, all errors can be divided into two categories: business errors, which result from the specifics of business rules and constraints, and technical errors – unexpected situations that the system must handle in a consistent and predictable manner.
Business Errors in DDD
Business errors are nothing more than restrictions in the domain model that clearly define what is allowed and what is not. This provides the customer with precise and understandable messages that reflect actual business rules. In DDD, it is the domain expert who decides how the system should respond to such situations – it is they who design the rules and boundaries that the system must respect.
I always model business exceptions explicitly (checked exception). They are clearly visible at the domain service level, and together with the expert, we model and determine the appropriate process response.
This approach increases code readability and makes business errors a natural part of the model rather than an unexpected exception.
Technical Errors in DDD
Technical errors are any unforeseen exceptions that should not affect the domain model. Usually, in order to understand the problem and the nature of a technical failure, I reduce it to the proverbial pulling the plug.
In my projects, modeling all technical failures as unchecked exceptions works well. First, technical errors do not obscure the model, and second, if something undesirable happens in the process, I want it to end immediately.
Consistent handling of technical errors, regardless of their source, helps maintain system stability and enables effective response to failures.
Wrapping Up: How to Build Code That Actually Serves the Business
Do you want your code to not only work, but also tell the story of your business? It's possible! In the world of modern programming, a contract is more than just a technical interface, and value is more than just a number with a decimal point. By using the Domain-Driven Design (DDD) approach, you can create systems that “reflect” business logic and communicate in a way that is understandable to all stakeholders.
I encourage you to experiment with DDD in your projects—you’ll see how your code comes to life and becomes more transparent. By clearly separating business errors from technical ones and intentionally managing system responses, you can build applications that are stable, resilient, and easier to maintain.
If you’re interested in this topic and would like to discuss it, feel free to reach out—you can find me on LinkedIn.
Best of luck building code that reflects the business! 🙂

Wojciech Kołodziej
Reactive Programming in Java: Insights, Traps to Avoid, and When It Truly Shines
Senior Java Developer in a Cross-Technology Team: Real-World Lessons & Insights
Improvisation as the Key to Effective Meetings: A Practical Guide for Facilitators
QA Specialist: What Software Quality Assurance Really Entails