
Na temat programowania reaktywnego powstało już mnóstwo artykułów, a nawet całkiem grube książki. Nie chciałem więc dokładać kolejnego kompendium „od A do Z”.
Zależy mi na tym, żeby dać Ci teoretyczne minimum, które sam chciałbym znać, zanim pierwszy raz zanurzyłem się w ten świat. Pokażę Ci różnicę między modelem thread-per-request a podejściem reaktywnym, opowiem o kilku błędach, na które sami wpadliśmy, i - co najważniejsze - wskażę, jakie pułapki czekają na początkujących.
Dzięki temu dostaniesz nie tylko teorię, ale też realny wgląd w to, co naprawdę potrafi pójść nie tak. A na koniec zastanowimy się wspólnie, czy w czasach wątków wirtualnych reaktywność w ogóle ma jeszcze sens.
Zaczynajmy!
Tradycyjny model thread-per-request
W klasycznym, intuicyjnym podejściu każdy request dostaje swój własny wątek. Jest to proste, czytelne i przez lata działało świetnie. Wątek ma pełny kontekst requestu i zwykle nie musisz walczyć z synchronizacją. A nawet jeśli musisz - Java ma do tego całkiem niezłe narzędzia.
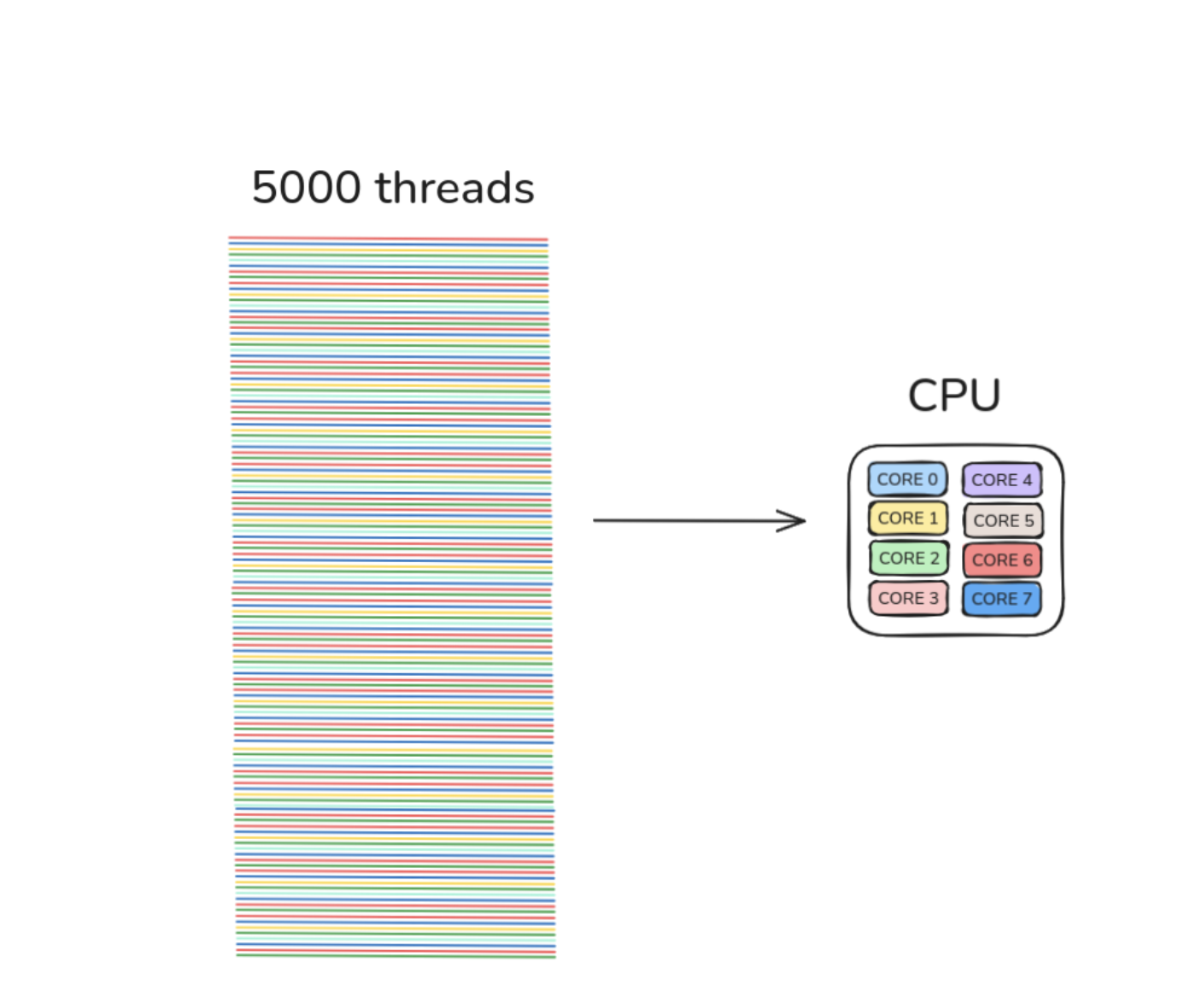
No ale… jak to zwykle bywa, diabeł tkwi w szczegółach. Każdy taki wątek jest wątkiem systemowym, a więc wymaga konkretnych zasobów. Upraszczając - ok. 1 MB pamięci na sztukę. Jeśli system jest w stanie komfortowo utrzymać, powiedzmy, 5000 wątków, to już wiesz, że wszystko ponad to zaczyna być problematyczne.
A teraz zestaw to z faktem, że masz np. 8-rdzeniowy CPU. Czyli:
5000 wątków rywalizuje o 8 miejsc przy stole.
Kilka z nich dostanie czas procesora, ale ogromna większość stoi w kolejce. Dochodzi koszt przełączania kontekstu, spowolnienia, no i klasyczne „dlaczego przy 2k req/s wszystko się dławi, skoro mamy tyle wątków?”.
To moment, w którym zaczęto szukać alternatyw. I tak dochodzimy do reaktywności.
O co chodzi w reaktywności?
Inny sposób myślenia
Żeby zrozumieć reaktywność, trzeba na chwilę odłożyć imperatywne podejście na półkę. Tutaj Twój kod nie mówi „zrób teraz”, tylko raczej „kiedy wydarzy się X, zrób Y”.
Jeśli programowałeś kiedykolwiek UI, to ten mindset nie będzie dla Ciebie nowy: kliknięcie przycisku, nadejście wiadomości, zmiana temperatury - to wszystko zdarzenia, na które reagujesz. I dopóki nie zasubskrybujesz się na dany strumień zdarzeń, Twój kod nawet nie ruszy.
Tak samo jest z HTTP, strumieniami danych, z czymkolwiek.
Event loop
W podejściu reaktywnym mamy niewielką, precyzyjnie dobraną pulę wątków, które obsługują pętlę zdarzeń (event loop). Może być ich tyle, ile rdzeni CPU, czasem trochę więcej. I to one ogarniają wszystkie requesty.
Po co tak drastycznie ograniczać liczbę wątków? Bo im mniej ich masz, tym mniej przełączania kontekstu i tym łatwiej wykorzystać CPU do maksimum.
Netty jest dobrym przykładem serwera działającego w tym modelu. Jeśli chcesz kiedyś wejść głębiej, zdecydowanie warto poczytać o tym, co tam się dzieje pod spodem.
Operacje nieblokujące
Kluczowe jest to, żeby event loop nigdy nie wykonywał operacji blokujących. Żadnego IO: ani do bazy, ani na dysk, ani po sieci.
Dlaczego? Bo procesor działa szybko… dopóki nie musi czekać. A operacje IO są dla niego jak stanie w kolejce w sobotę o 17:00 w supermarkecie. Możesz mieć kilka kas (wątki), ale jeśli ktoś robi gigantyczne zakupy, cała kolejka stoi.
W aplikacji reaktywnej takich „klientów” mogą być tysiące, a kas - 16. Wystarczy kilka blokujących operacji i cała architektura przestaje oddychać.
Rozwiązanie? Jeśli musisz zrobić IO - robisz je na osobnej puli wątków. Wtedy nie blokujesz event loop i świat dalej się kręci.
Inne zalety
Reaktywność to nie tylko lepsze wykorzystanie CPU. Daje też świetne możliwości przetwarzania strumieni danych.
Przykład: zamiast czekać na całą listę obiektów, przetwarzasz elementy w locie, gdy tylko nadejdą. Oszczędzasz pamięć, zyskujesz czas.
Można powiedzieć: „da się to zrobić na wątkach”. Jasne, da się - tylko po co się męczyć? W reaktywności API do operacji na strumieniach jest wygodne, czytelne i bogate: łączenie strumieni, buforowanie, obsługa błędów, backpressure… wszystko na miejscu, bez ręcznego spinania synchronizacji.
W świecie concurrency to naprawdę dużo.
Moje doświadczenia z reaktywnością
W XTB korzystamy z podejścia reaktywnego w wielu aplikacjach, głównie na bazie Project Reactor. Przez ostatnie trzy lata pisałem sporo mikroserwisów w Micronaucie korzystających właśnie z Reactora. I powiem wprost: początki są trudne. Testowanie - jeszcze trudniejsze. Debugowanie? To już w ogóle sport ekstremalny.
Flow potrafi błądzić między wątkami, a to, co myślisz, że się stanie… często się nie dzieje.
Mam za sobą i widziałem naprawdę dużo bugów wynikających z nieoczywistych zachowań Reactora. I właśnie o kilku z nich opowiem dalej - tak ku przestrodze.
Jak zacząć z Project Reactorem?
Przede wszystkim zacznij od przejrzenia materiałów edukacyjnych na https://projectreactor.io/learn. To naprawdę solidny punkt startowy - zwłaszcza jeśli wolisz uczyć się na krótkich, konkretnych przykładach, a nie tonąć w abstrakcjach. Wśród materiałów znajdziesz m.in. repozytorium z praktycznymi ćwiczeniami: https://github.com/schananas/practical-reactor
Po ich przerobieniu powinieneś mieć już podstawową znajomość Reactora, która pozwoli Ci zacząć pracować nad nowymi funkcjonalnościami.
Jeśli szukasz bardziej zaawansowanych materiałów, to na YouTube jest świetny tech talk, który dogłębnie opisuje, jak działa Reactor:
Na tym etapie może Ci się wydawać, że już wiesz dużo, ale kiedy przyjdzie czas na własnoręczne napisanie testów… może się okazać, że program działa zupełnie inaczej niż sobie wyobrażałeś. Testowanie aplikacji reaktywnej jest bardzo ważne. Zwłaszcza, jeśli jesteś początkujący.
Co jeśli wystąpi błąd na strumieniu? Czy subscriber wykona retry? Co jeśli backpressure będzie przepełniony? Co jeśli różne wątki wyemitują jednocześnie różne wartości na sink?
I tak dalej…
Jeśli zauważyłeś, że program działa inaczej niż się spodziewałeś, to znalezienie przyczyny i rozwiązanie tego potrafi być dużym wyzwaniem. Debugowanie jest utrudnione przez to, że całe flow może być rozrzucone po różnych wątkach. Czasami trzeba naprawdę głęboko wejść w dokumentację.
Najczęstsze błędy i pułapki w reaktywności
Gdy już poznasz podstawy i pobawisz się prostymi przykładami, bardzo szybko trafisz na sytuacje, w których „coś tu nie gra”. Reactor jest potężny, ale potrafi być nieintuicyjny. Dlatego poniżej zebrałem kilka pułapek, w które najłatwiej wpaść na początku.
Błędne korzystanie z flatMap
Zaburzona kolejność
To klasyczny błąd. Mamy chronologiczny strumień eventów:
Flux<Event> stream = ... // EVENT_1, EVENT_2, EVENT_3...
I funkcję:
Mono<EventDetails> fetchDetailsFor(Event event) { … }
Kusi, żeby napisać:
stream.flatMap(event -> fetchDetailsFor(event)).subscribe(...)
Co w tym złego?
flatMap działa współbieżnie - odpala zapytania współbieżnie i nie gwarantuje kolejności. Efekt końcowy może wyglądać tak:
EVENT_3 → EVENT_1 → EVENT_2
Jeśli kolejność jest istotna, trzeba użyć concatMap albo flatMapSequential.
„Zagłodzone” streamy
Drugi scenariusz: łączymy ticki wielu par walutowych (czyli tykające wartości kursów):
Flux<CurrencyPair> currencyPairs = getAllCurrencyPairs();
Flux<Tick> ticks = currencyPairs.flatMap(cp -> listenToTicks(cp));
Brzmi niewinnie, ale flatMap ma domyślny concurrency = 256. Jeśli masz 500 par walutowych (albo więcej - a jest ich teoretycznie 32k), większość strumieni nigdy nie zobaczy demandu (request(n)), więc nigdy nic nie wyemituje.
Chcesz wszystkie? Musisz ustawić concurrency ≥ liczbie strumieni.
Niepoprawne korzystanie z sinka
Sinks są super - dopóki nie wyemitujesz błędu. Rozważ:
while (true) {
try {
sink.emitNext(calculateScore(), FAIL_FAST);
} catch (...) {
sink.emitError(e, FAIL_FAST);
}
}
W momencie emitError sink jest już martwy. Każdy nowy subskrybent dostanie od razu error. Nie ma retry, nie ma nowych danych - nic. Taki sink nadaje się tylko do wymiany.
Druga pułapka - autoCancel = true. Jeśli ostatni subskrybent się odsubskrybuje, sink się zamyka. I nie emituje już więcej. To potrafi zaskoczyć.
Niepoprawne łączenie snapshotu z subskrypcją zmian
Chcemy mieć:
- aktualny snapshot,
- a potem bieżące zmiany.
Kod wydaje się być w porządku:
Mono<Portfolio> snapshot = Mono.defer(() -> readPortfolioSnapshot());
Flux<Portfolio> changes = Flux.defer(() -> listenToPortfolioChanges());
return Flux.mergeSequential(snapshot, changes);
Wygląda dobrze, ale jest problem: minimalne opóźnienie pomiędzy subskrypcjami potrafi „zgubić” update, który wydarzy się pomiędzy pobraniem snapshotu a zasubskrybowaniem zmian.
Dokumentacja mówi „eager subscription”, ale według issue na GitHubie demand na kolejne źródła jest zgłaszany dopiero po zakończeniu poprzednich.
Rozwiązanie? Nie używać defer przy changes:
Mono<Portfolio> snapshot = Mono.defer(() -> readPortfolioSnapshot());
Flux<Portfolio> changes = listenToPortfolioChanges();
return Flux.mergeSequential(snapshot, changes);
Snapshot ma być leniwy - stream zmian nie.
Czy reaktywność ma sens, skoro mamy wątki wirtualne?
Wraz z wejściem wątków wirtualnych podejście thread-per-request dostało drugie życie. Wątki są lekkie, szybkie, można ich tworzyć tysiące (bo nie odzwierciedlają 1:1 wątków systemowych). To brzmi jak „problem solved, idziemy do domu”.
Ale nadal obowiązują prawa fizyki. Milion wirtualnych wątków wykonujących intensywne obliczenia nie będzie szybszy niż 8 rdzeni. IO? Owszem - tutaj wątki wirtualne błyszczą, bo podczas czekania oddają CPU innym. Ale cały czas alokują pamięć, istnieją w oczach GC, więc skala ma znaczenie.
Czyli co? Znowu reaktywność?
Moim zdaniem: to zależy.
Jeśli obsługujesz zwykłe request–response - wątki wirtualne są dziś świetnym wyborem. Warto też wspomnieć o structured concurrency, które dodatkowo upraszcza klasyczne podejście. Jeśli jednak masz strumienie danych, na których wykonujesz dużo operacji - reaktywność nadal ma realne przewagi, zwłaszcza w połączeniu z server-side streamingiem (np. gRPC).
Podsumowanie
Masz już ogólny obraz tego, czym jest reaktywność i kiedy ma sens. Przeszliśmy przez kilka pułapek, które spotkaliśmy w trakcie developmentu i które, mam nadzieję, oszczędzą Ci trochę czasu (i nerwów).
Jeśli pracujesz w środowisku opartym o strumienie, reaktywność może być mocnym narzędziem. Ale w większości przypadków nie musisz po nią sięgać - wątki wirtualne naprawdę potrafią upraszczać życie.
Jeśli temat Cię zaciekawił albo masz własne doświadczenia (albo wojenne historie…), zapraszam do kontaktu. Znajdziesz mnie na LinkedIn.


QA Specialist - na czym naprawdę polega praca w zapewnianiu jakości oprogramowania?
Praca Senior Java Developera w zespole cross-technologicznym - doświadczenia i wskazówki
Improwizacja kluczem do prowadzenia spotkań - praktyczny przewodnik dla facylitatorów
Ta publikacja handlowa jest informacyjna i edukacyjna. Nie jest rekomendacją inwestycyjną ani informacją rekomendującą lub sugerującą strategię inwestycyjną. W materiale nie sugerujemy żadnej strategii inwestycyjnej ani nie świadczymy usługi doradztwa inwestycyjnego. Materiał nie uwzględnia indywidualnej sytuacji finansowej, potrzeb i celów inwestycyjnych klienta. Nie jest też ofertą sprzedaży ani subskrypcji. Nie jest zaproszeniem do nabycia, reklamą ani promocją jakichkolwiek instrumentów finansowych. Publikację handlową przygotowaliśmy starannie i obiektywnie. Przedstawiamy stan faktyczny znany autorom w chwili tworzenia dokumentu. Nie umieszczamy w nim żadnych elementów oceniających. Informacje i badania oparte na historycznych danych lub wynikach oraz prognozy nie stanowią pewnego wskaźnika na przyszłość. Nie odpowiadamy za Twoje działania lub zaniechania, zwłaszcza za to, że zdecydujesz się nabyć lub zbyć instrumenty finansowe na podstawie informacji z tej publikacji handlowej. Nie odpowiadamy też za szkody, które mogą wynikać z bezpośredniego czy też pośredniego wykorzystania tych informacji. Inwestowanie jest ryzykowne. Inwestuj odpowiedzialnie.