
Au cours des dernières années, la révolution de l'intelligence artificielle s'est peu à peu résumée à un discours d'investissement très simple. Au cœur de ce récit se trouve un seul protagoniste : le GPU. Les processeurs graphiques sont devenus le symbole d'une nouvelle ère technologique, et leur disponibilité a directement déterminé quelles entreprises sont capables de former les modèles linguistiques les plus avancés, et lesquelles sont laissées pour compte dans la course vers l'avenir de l'IA
En conséquence, le marché a rapidement appris à envisager l'intelligence artificielle à travers un seul indicateur : la puissance de calcul. Plus de GPU signifiait des modèles plus grands, des modèles plus grands signifiaient de meilleurs produits, et de meilleurs produits signifiaient un avantage concurrentiel.
Au fil du temps, cependant, ce discours a commencé à se complexifier. Il s’est avéré que la puissance de calcul brute ne suffisait pas si le système était incapable de fournir les données à la vitesse requise. Le goulot d’étranglement ne se situait plus uniquement au niveau des GPU, mais de plus en plus au niveau de la mémoire, tant la mémoire la plus proche du processeur sous forme de HBM que la DRAM traditionnelle des serveurs, ainsi que l’ensemble de l’infrastructure de stockage et de transfert de données.
C'est à ce moment-là que les investisseurs ont commencé à réaliser que la révolution de l'IA ne se résume pas à un seul composant, mais à toute une chaîne technologique, du silicium à la mémoire, en passant par les réseaux et les systèmes de refroidissement.
Et aujourd'hui, alors que la carte de cette révolution semblait relativement complète, un autre changement se profile, bien moins évident, mais potentiellement tout aussi important que les précédents.
Une couche qui, pendant des années, a été considérée comme une « infrastructure évidente » joue désormais un rôle de plus en plus important : le CPU. Dans un monde où l’IA n’est plus une simple requête adressée à un modèle, mais ressemble plutôt à un système complexe d’agents autonomes exécutant des tâches en plusieurs étapes, ce n’est pas seulement l’échelle du calcul qui change, mais surtout sa nature.
À ce stade, une question se pose qui semblait secondaire il n’y a pas si longtemps. Le CPU, qui agissait auparavant comme un coordinateur et un partenaire discret du GPU, serait-il en train de devenir l’un des composants clés de l’architecture IA dans son ensemble ?
Et si tel est le cas, cela signifie-t-il que nous entrons dans une troisième vague de la révolution de l’IA après les GPU et la mémoire, dans laquelle le facteur clé ne sera plus la puissance de calcul brute, mais plutôt notre capacité à connecter et à orchestrer l’ensemble du système?
L'ÈRE DU GPU
Au début de la révolution de l'IA, peu de doutes subsistaient quant à l'origine de ses fondements technologiques. Avec les avancées décisives en matière d'apprentissage profond et l'apparition de modèles linguistiques de plus en plus volumineux, il est rapidement apparu que la principale limite ne résidait plus dans l'algorithme lui-même, mais dans l'ampleur des calculs nécessaires à son apprentissage.
C'est à ce moment-là que les processeurs graphiques ont pris le devant de la scène. Leur architecture, initialement conçue pour le rendu graphique et le traitement parallèle d'images, s'est avérée parfaitement adaptée au type de calcul requis par les réseaux neuronaux. Au lieu d'un seul cœur très rapide, les GPU offrent des milliers d'unités de traitement plus simples, capables d'effectuer les mêmes opérations en parallèle sur d'énormes ensembles de données.
C'est ce qui a fait des GPU le moteur naturel de la révolution de l'IA. L'entraînement des modèles linguistiques, en particulier ceux basés sur des architectures de transformateurs, se résume en grande partie à des opérations matricielles, des tâches qui peuvent être facilement parallélisées. En pratique, cela signifiait que plus la puissance des GPU pouvait être concentrée dans un seul système, plus le modèle pouvant être entraîné était grand.
En conséquence, une nouvelle norme en matière d’infrastructure de calcul a rapidement émergé. Les centres de données ont commencé à ressembler à des grappes d’accélérateurs spécialisés, où les processeurs (CPU) jouaient un rôle de soutien, principalement chargé de la préparation des données, de la gestion des processus et de la communication entre les composants du système. Tous les « calculs mathématiques lourds » ont été transférés vers les GPU.
Cette architecture a conduit à une forte concentration de valeur dans un seul segment du marché. À mesure que la demande en puissance de calcul augmentait, les fabricants de GPU se sont approprié la plus grande part de la valeur économique de la révolution de l’IA. L'accès aux GPU est devenu non seulement un avantage technologique, mais aussi une contrainte stratégique déterminant le rythme de développement d'entreprises et de laboratoires de recherche tout entiers.
Dans ce contexte, le marché a commencé à envisager l'IA de manière très linéaire. Plus de GPU signifiait plus de puissance de calcul, plus de puissance de calcul signifiait des modèles plus grands, et des modèles plus grands signifiaient de meilleurs produits. La logique de cette révolution semblait relativement simple et bien comprise.
Ce n'est qu'avec le temps que les premiers signes ont montré que ce tableau était incomplet.
LA MÉMOIRE COMME DEUXIÈME VAGUE
À mesure que les modèles d'IA passaient de quelques millions à des milliards, puis à des centaines de milliards de paramètres, un problème est apparu, qui n'était pas aussi évident au départ que le manque de puissance de calcul. Il s'est avéré que le simple fait d'augmenter le nombre de GPU ne résolvait pas toutes les limites du système si les données ne pouvaient pas circuler assez rapidement à travers l'ensemble de l'architecture de calcul.
C'est à ce moment-là que la mémoire a commencé à occuper le devant de la scène. Tant la mémoire directement connectée aux GPU sous forme de HBM que la DRAM traditionnelle des serveurs, ainsi que l'ensemble de la couche de stockage et de transfert de données dans les centres de données. La mémoire est devenue le facteur déterminant la vitesse à laquelle des modèles de plus en plus volumineux pouvaient être entraînés et exécutés.
En pratique, cela signifiait que même les GPU les plus avancés étaient incapables d'exploiter pleinement leur potentiel s'ils n'étaient pas correctement « alimentés » en données. Le goulot d'étranglement n'était plus le calcul lui-même, mais la capacité du système à maintenir un flux continu d'informations entre la mémoire, le réseau et les accélérateurs.
C'est à ce moment-là que la révolution de l'IA a commencé à passer d'un problème purement computationnel à un problème de systèmes. Au lieu d'un composant dominant unique, nous avons commencé à observer une dépendance de plus en plus complexe entre les différentes couches de l'infrastructure.
La mémoire, auparavant considérée comme un élément de soutien, a commencé à jouer un rôle stratégique. Les solutions à large bande passante telles que la HBM sont devenues l’un des principaux catalyseurs de la mise à l’échelle des modèles modernes, et les fabricants de mémoire ont commencé à occuper une place plus importante dans la chaîne de valeur de la révolution de l’IA.
Il est important de noter que cette étape n’a pas remplacé les GPU, mais a plutôt révélé leurs limites naturelles. À mesure que les modèles évoluaient, il est devenu évident que la puissance de calcul seule n'avait aucune valeur si elle n'était pas soutenue par un débit de données suffisant. En conséquence, le marché a progressivement commencé à reconnaître que l'IA n'était pas une course unique au processeur le plus puissant, mais un système complexe dans lequel chaque composant de l'infrastructure pouvait devenir un goulot d'étranglement potentiel.
C'est à ce moment-là qu'une compréhension plus complète de l'IA en tant qu'écosystème a commencé à se former, où, aux côtés des GPU, la mémoire, les réseaux et l'infrastructure de données jouent tous des rôles essentiels.
LE CPU ET L'ESSOR DE L'IA AGENTIQUE
Pendant longtemps, le rôle des processeurs (CPU) dans la révolution de l'IA semblait relativement stable et bien défini. Ils étaient chargés de la gestion du système, de la préparation des données et de la coordination du travail des accélérateurs graphiques (GPU), qui se chargeaient des tâches de calcul intensif. Dans cette configuration, le processeur agissait comme un opérateur d'infrastructure discret, invisible du point de vue de l'utilisateur final et dont la fonction restait largement inchangée.
Cette image est en train de changer avec l'émergence d'une nouvelle catégorie d'applications d'IA, de plus en plus souvent appelée « IA agentique ». Contrairement aux modèles linguistiques traditionnels qui répondent à des invites uniques, les systèmes basés sur des agents sont conçus pour effectuer des tâches complexes en plusieurs étapes qui nécessitent non seulement de générer des réponses, mais aussi d'entreprendre des actions au sein d'un environnement numérique.
En pratique, cela signifie qu’au lieu d’une simple requête et d’une simple réponse, nous avons affaire à toute une chaîne d’opérations. Un agent peut commencer par analyser un problème, puis le décomposer en étapes plus petites, exécuter une série de requêtes vers des systèmes externes, des bases de données ou des API, traiter les informations obtenues, et ce n’est qu’ensuite qu’il produit un résultat final. Chacune de ces étapes nécessite des opérations système distinctes, une communication avec différentes sources de données et une gestion continue de l’état de l’ensemble du processus.
Dans ce nouveau modèle, la charge de calcul commence à se déplacer. Le modèle linguistique s’exécutant sur le GPU ne devient qu’une partie d’un système plus vaste, chargé de la génération et de l’interprétation du langage. Le reste, logique de contrôle, gestion des tâches, communication entre les systèmes et gestion des outils externes, sollicite de plus en plus le CPU.
C'est là qu'apparaît un changement fondamental de perspective. Auparavant, le CPU était considéré comme une couche de soutien dont le rôle était de « ne pas gêner » le calcul du GPU. Dans le monde de l'IA agentique, cependant, le CPU commence à agir comme un coordinateur actif qui non seulement gère le flux de données, mais participe également au processus décisionnel du système.
Il est important de noter qu’il ne s’agit pas d’un changement cosmétique, mais d’un changement structurel. Chaque agent IA effectue non pas une, mais de nombreuses étapes de calcul et d’exécution, ce qui entraîne une forte augmentation des opérations exécutées en dehors du GPU. En conséquence, l’importance de l’infrastructure CPU s’accroît, car elle doit gérer en parallèle un nombre massif de requêtes, de processus et d’interactions en temps réel.
C'est à ce stade que le premier véritable changement architectural dans les systèmes d'IA devient visible. Au lieu d'un modèle centré sur un seul type de calcul, nous évoluons vers un système multicouche dans lequel différents composants sont chargés de différents rôles opérationnels. Les GPU gèrent les calculs matriciels, la mémoire gère le stockage et le flux de données, tandis que les CPU deviennent de plus en plus la couche chargée de l'orchestration de l'ensemble du processus.
L'ÉVOLUTION DE L'ARCHITECTURE DES SYSTÈMES
Avec le rôle croissant de l'IA agentique, ce n'est pas seulement la manière dont les modèles sont utilisés qui change, mais l'architecture même des systèmes d'IA. La répartition traditionnelle, où les GPU se chargeaient des calculs et les CPU jouaient un rôle de soutien, s'avère de plus en plus inadéquate pour le fonctionnement réel des applications d'IA modernes.
Au lieu d'un processus de calcul unique, nous avons de plus en plus affaire à un système ressemblant à un réseau complexe de couches coopératives. Le modèle linguistique reste le cœur du « raisonnement », mais autour de lui se développe une infrastructure étendue chargée de la mémoire, du flux de données, de la communication avec les outils et de l'exécution en temps réel.
Dans une telle configuration, le CPU n’est plus seulement une couche de support technique pour le GPU, mais devient l’intégrateur de l’ensemble du système. Il assume désormais une part croissante des responsabilités liées à l’orchestration, à la gestion de l’état et à la gestion de processus complexes basés sur des agents.
En conséquence, l’IA cesse d’être un modèle unique et devient un système d’exploitation pour des processus intelligents, dans lequel différents types de matériel jouent des rôles spécialisés mais interdépendants.
L'ÉCONOMIE DU CHANGEMENT
Le changement le plus important qui s'opère actuellement dans l'ensemble de l'infrastructure de l'IA ne concerne pas la manière dont les systèmes sont construits, mais la façon dont la demande en ressources de calcul est répartie. Pendant longtemps, le point de référence dominant a été le rapport CPU/GPU, qui, dans les clusters d'IA traditionnels, était fortement déséquilibré en faveur des accélérateurs.
Avec l'essor de l'IA agentique, cet équilibre évolue progressivement. Au lieu d'une architecture où les CPU jouent un rôle marginal et où les GPU dominent le système, nous nous dirigeons vers un modèle plus équilibré dans lequel les processeurs à usage général prennent en charge une part croissante des charges de travail liées à l'orchestration, à la gestion des outils et au traitement en plusieurs étapes.
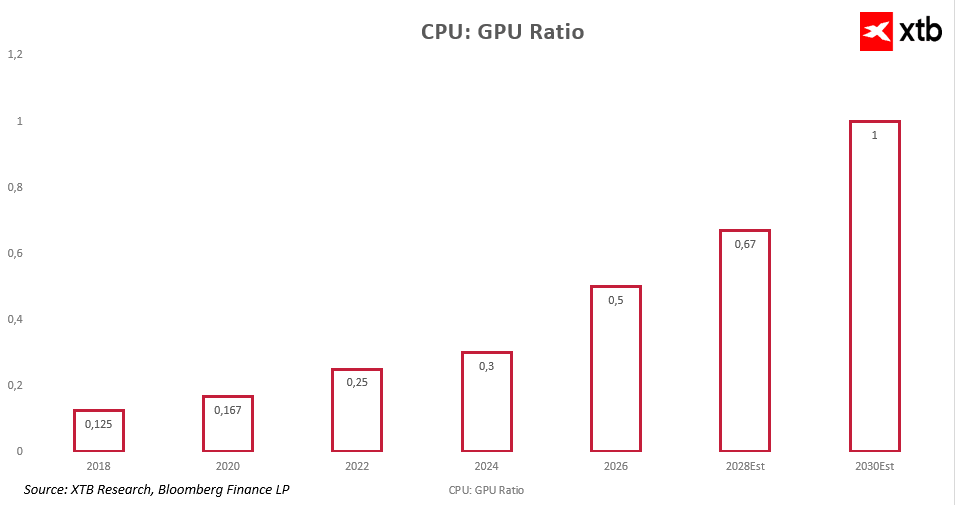
Cette évolution a des conséquences économiques directes. À mesure que de plus en plus d'opérations sont déchargées des GPU, la demande en puissance de calcul des CPU dans les centres de données augmente, ce qui se traduit par un besoin accru de cœurs par accélérateur. En conséquence, les infrastructures d'IA deviennent plus gourmandes en ressources, non seulement en termes de GPU, mais aussi en matière de calcul généraliste.
Du point de vue des systèmes, cela entraîne une réorientation structurelle de la demande tout au long de la chaîne de valeur. Les dépenses d'investissement, qui se concentraient auparavant principalement sur les GPU et la mémoire à large bande passante, s'étendent de plus en plus au segment des CPU. Cela exerce une pression sur les chaînes d'approvisionnement, augmente l'utilisation des capacités de production et redéfinit progressivement les attentes concernant le marché des CPU pour serveurs.
Dans ce contexte, le CPU n'est plus considéré comme un segment mature et stable, mais plutôt comme l'un des composants clés de l'infrastructure d'IA, dont l'importance croît avec la complexité des systèmes basés sur des agents.
LE MARCHÉ DES PROCESSEURS ET LES PRINCIPAUX ACTEURS
L'évolution du rôle des processeurs dans l'architecture de l'IA est en train de redessiner le paysage concurrentiel de l'industrie des semi-conducteurs. Pendant de nombreuses années, le marché des processeurs pour serveurs est resté relativement stable et dominé par un seul acteur, mais avec l'avènement de l'ère de l'IA agentique, il redevient un terrain de concurrence technologique intense.
Au cœur de cette concurrence se trouvent trois forces principales : AMD, Intel et Arm. Chacune représente un modèle économique, une architecture et une approche différents de ce que devrait être un processeur moderne à l'ère de l'IA.
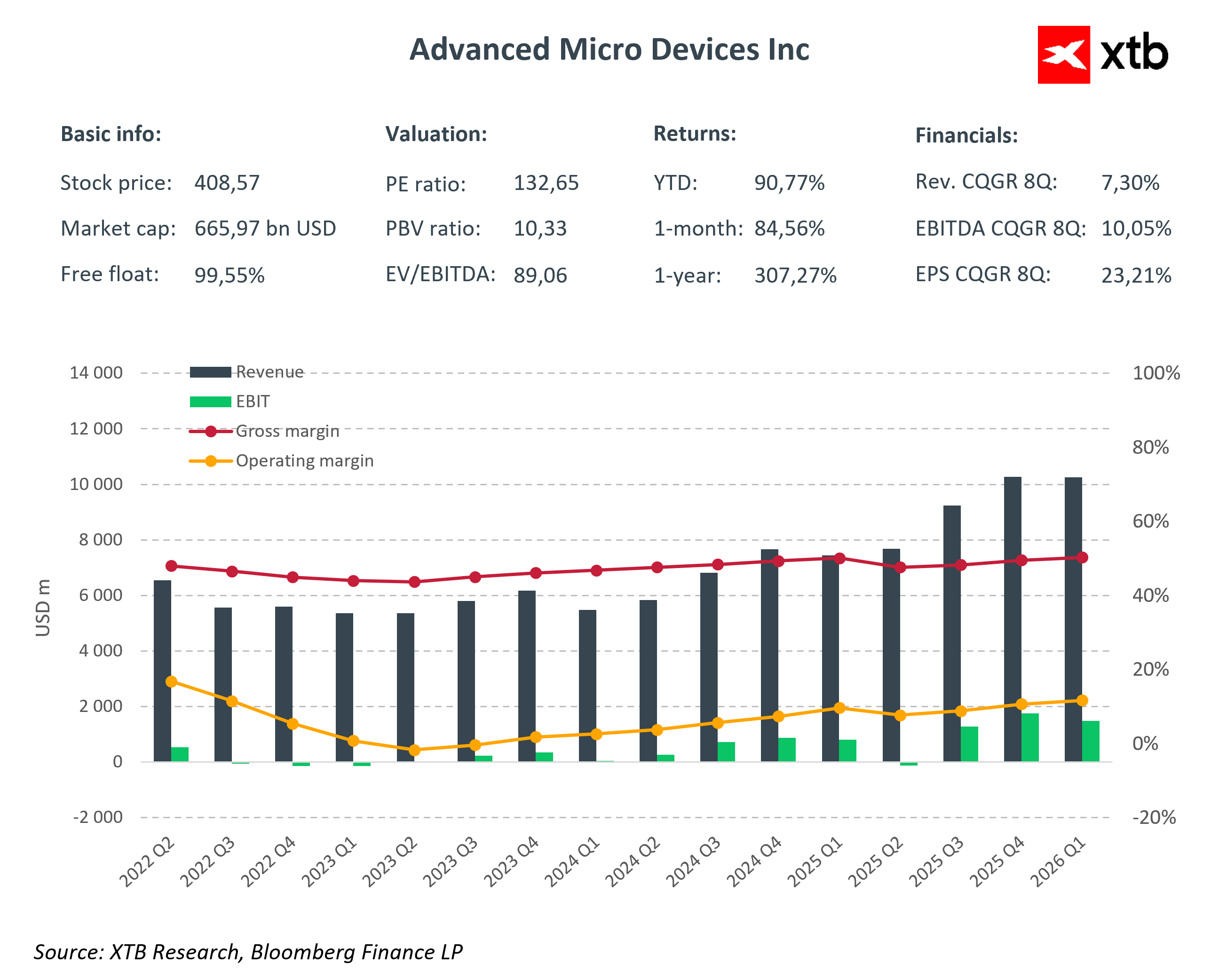
AMD est le bénéficiaire le plus direct des changements survenus dans le segment des serveurs x86. Grâce à ses processeurs EPYC, l'entreprise augmente régulièrement sa part de marché tout en offrant une excellente efficacité énergétique et des performances par cœur compétitives. Dans un contexte de demande croissante en processeurs pour les systèmes basés sur des agents, AMD tire également parti de sa capacité à fournir à la fois des processeurs et des cartes graphiques, construisant ainsi une pile informatique plus complète pour les centres de données.
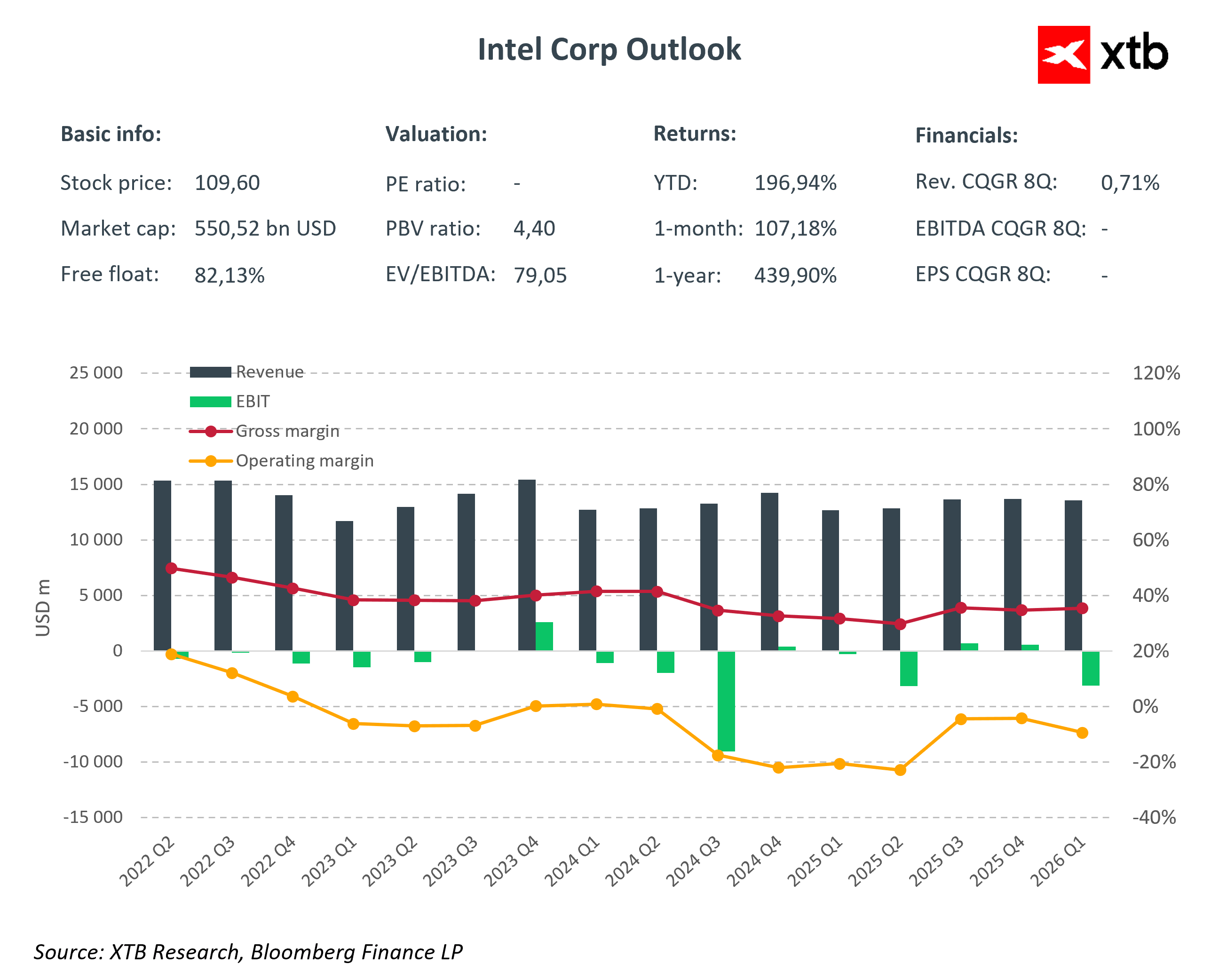
Intel, quant à lui, est en pleine phase de transformation. Après avoir perdu des parts de marché dans le secteur des serveurs pendant des années, l'entreprise tente de regagner du terrain grâce à de nouvelles générations de processeurs Xeon et à une stratégie axée sur l'amélioration de ses procédés de fabrication. Cependant, le défi auquel Intel est confronté n'est pas seulement technologique, mais aussi stratégique : il s'agit de redéfinir son rôle au sein d'un écosystème de l'IA qui a largement évolué en dehors de ses domaines de compétence traditionnels.
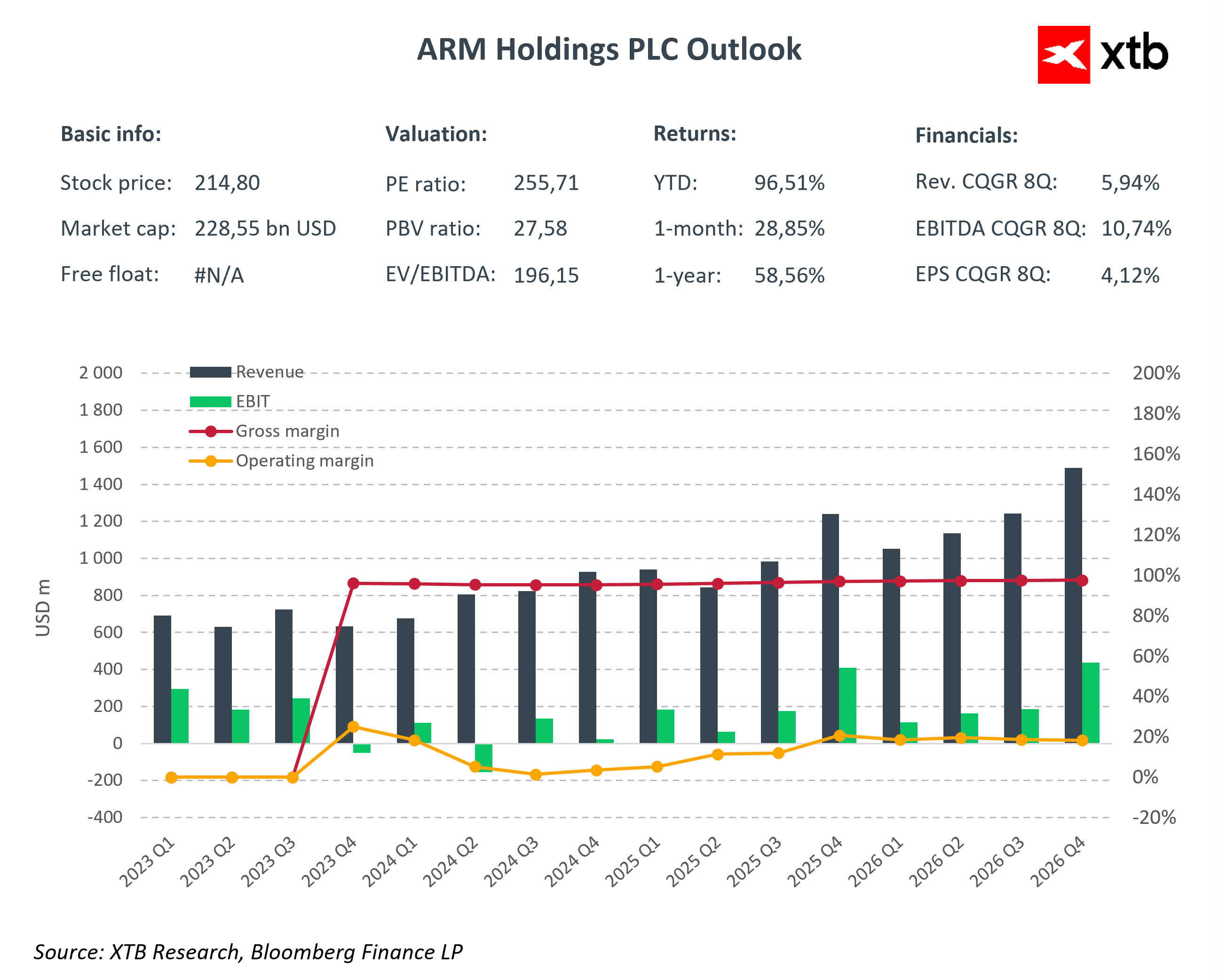
Le troisième pilier est Arm, qui opère à un autre niveau de la chaîne de valeur. Plutôt que de fabriquer des puces, Arm fournit l'architecture utilisée par les hyperscalers pour concevoir leurs propres processeurs. De ce fait, une part croissante de la croissance du marché des processeurs ne profite pas directement aux fabricants traditionnels, mais plutôt aux écosystèmes cloud qui développent des puces sur mesure.
Cela entraîne une transformation structurelle. Le marché des processeurs n'est plus un simple duopole entre Intel et AMD, mais un écosystème à plusieurs niveaux où des hyperscalers tels qu'AWS, Google et Microsoft conçoivent leurs propres processeurs, optimisés pour des charges de travail spécifiques.
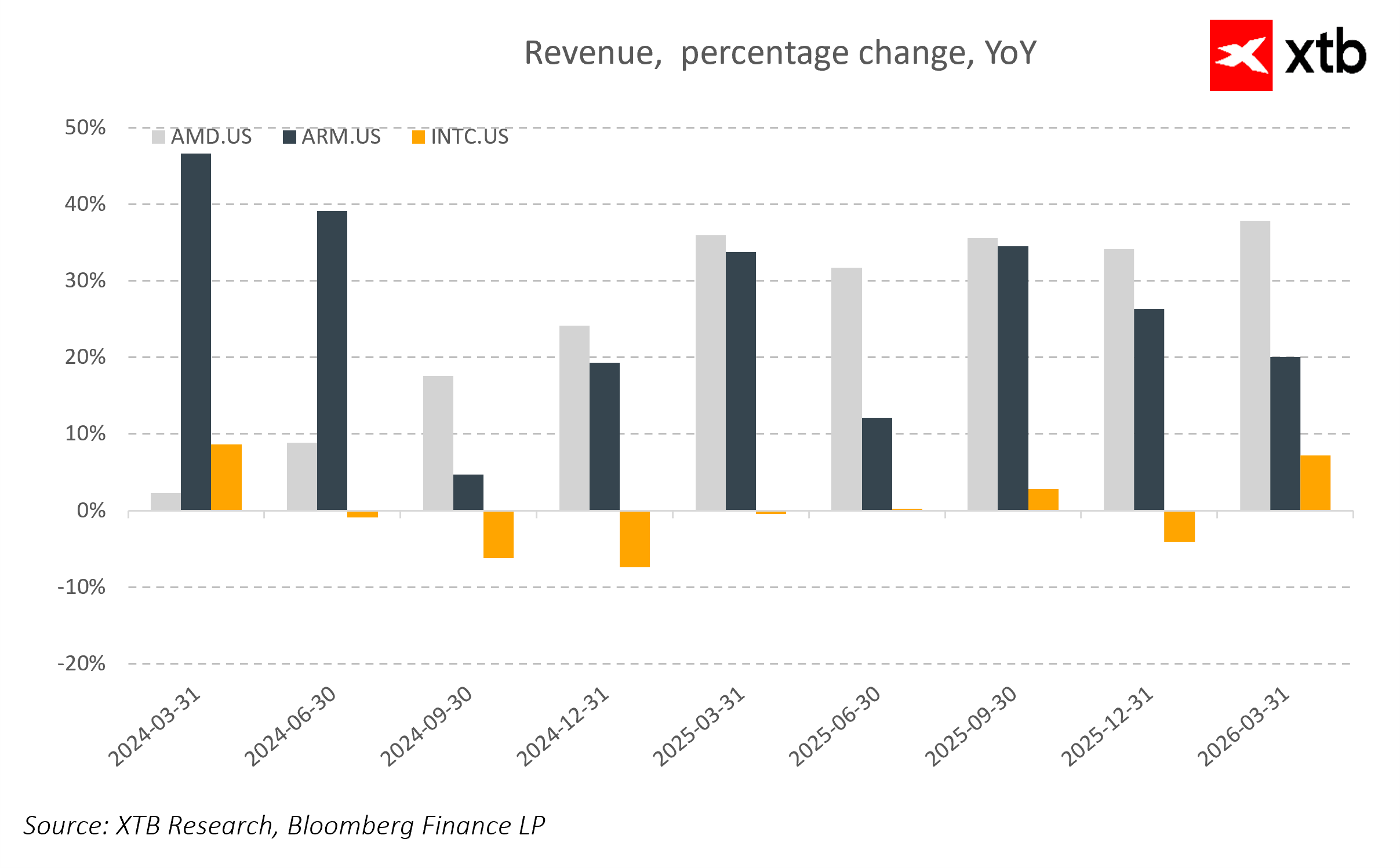
Dans ce contexte, il n'y a pas de vainqueur incontesté. On observe plutôt un marché où différents modèles commerciaux et architecturaux coexistent et se disputent une part croissante de la demande en puissance de calcul à l'ère de l'IA.
LA TROISIÈME VAGUE DE L'IA ET SES IMPLICATIONS
Si l'on examine l'ensemble de la révolution de l'IA sous l'angle des infrastructures, un schéma d'évolution clair se dessine, dans lequel les couches successives du système passent progressivement de l'arrière-plan au premier plan. Il y a d'abord eu le calcul sur GPU, qui a rendu possibles les modèles linguistiques modernes. Puis la mémoire s'est imposée au premier plan, sans laquelle la mise à l'échelle n'aurait pas été possible. Aujourd'hui, les processeurs (CPU) s'imposent de plus en plus comme la couche suivante de cette chaîne.
Cette évolution n'est pas dictée par une mode technologique, mais par une évolution fondamentale du fonctionnement des systèmes d'IA. Le passage des requêtes ponctuelles aux modèles linguistiques, puis à l'IA agentique, représente une transition des calculs simples vers des processus décisionnels complexes en plusieurs étapes. Dans un tel environnement, l'importance de la gestion des tâches, de la communication avec les systèmes externes et de la gestion des opérations parallèles augmente considérablement.
Ce sont précisément ces fonctions qui sollicitent de plus en plus les processeurs, qui ne constituent plus une couche de soutien, mais une composante intégrante du fonctionnement des systèmes d'IA.
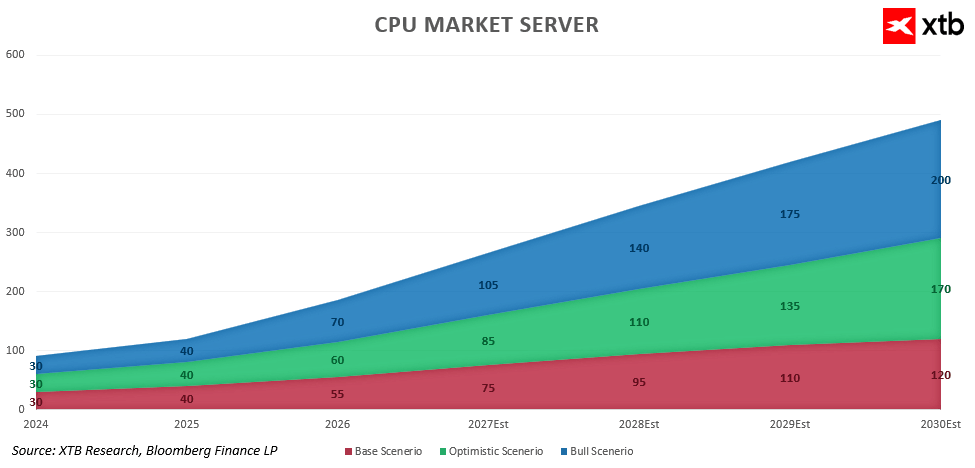
Cela conduit à une révision en profondeur des prévisions concernant la taille du marché des processeurs pour serveurs. Les projections, qui tablent sur une croissance dépassant les 120 milliards de dollars d'ici 2030, voire jusqu'à 200 milliards de dollars dans les scénarios les plus optimistes, indiquent que le segment des processeurs n'est plus un marché mature et stable, mais qu'il s'agit plutôt d'un cycle de croissance distinct, porté par l'IA.
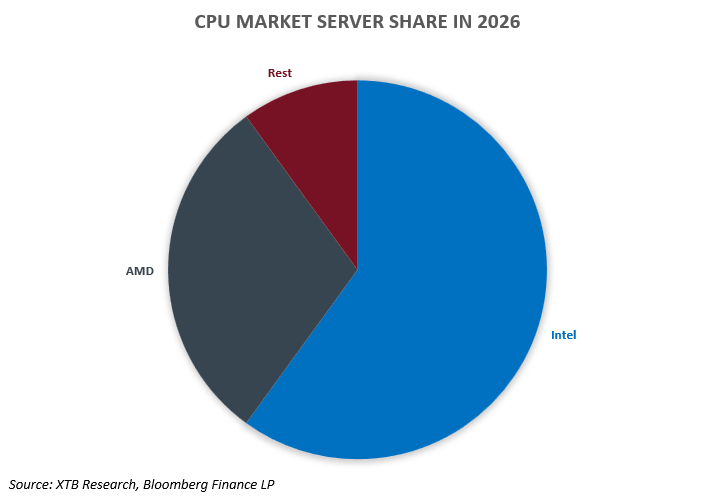
Dans ce nouveau paysage, il n'y a pas de vainqueur incontestable. AMD tire parti de la demande croissante sur le segment x86 et renforce sa position d'acteur clé dans le domaine des infrastructures d'IA. Intel tente de tirer parti du regain d'importance des processeurs pour se repositionner, tout en faisant face à des défis technologiques et concurrentiels. Quant à Arm, l'entreprise s'approprie une part croissante de la croissance du cloud, où les hyperscalers conçoivent des puces sur mesure pour des charges de travail spécifiques.
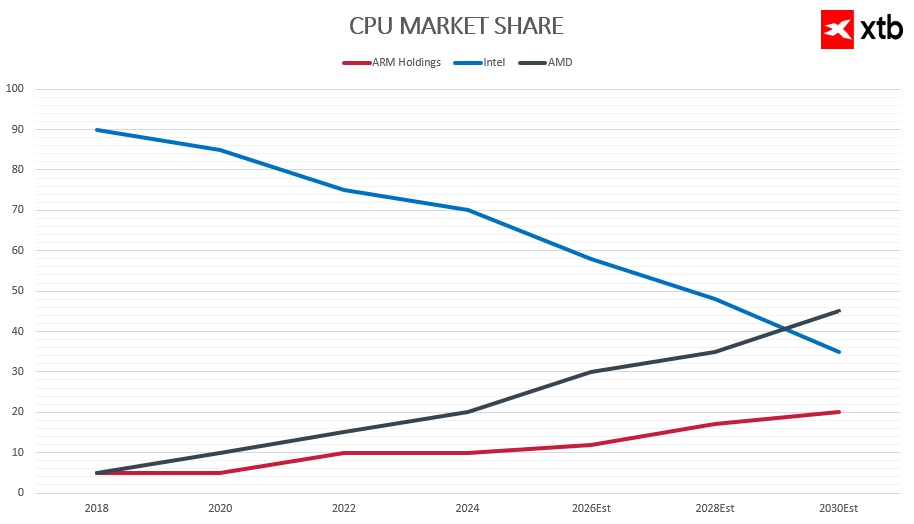
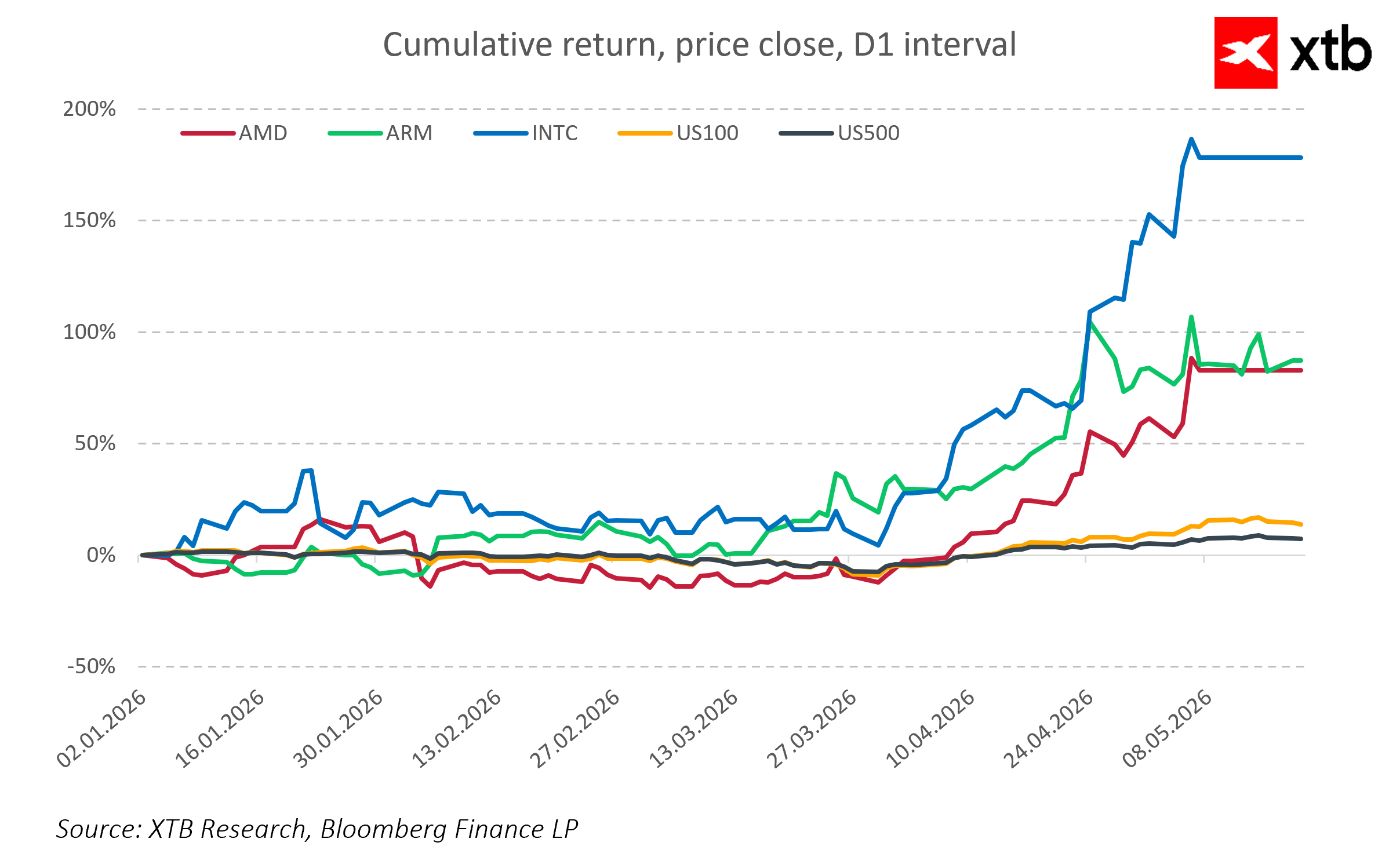
L'essentiel n'est pas d'identifier un seul grand gagnant, mais de comprendre que le CPU est en train de devenir une troisième vague parallèle de la révolution de l'IA, aux côtés des GPU et de la mémoire. Une vague qui ne remplace pas les précédentes, mais les complète, offrant ainsi une vision plus complète de l'infrastructure de l'IA.
Dans cette optique, la révolution de l'IA n'est plus l'histoire d'une seule percée technologique, mais un processus en plusieurs étapes de redistribution de la valeur à travers la chaîne de valeur des semi-conducteurs. Et le CPU, longtemps considéré comme un composant secondaire, commence à occuper dans ce système une place que peu de gens auraient imaginée il y a peu.

Le secteur du SaaS a-t-il trop perdu ? Morgan Stanley répond par l'affirmative.

Le Nasdaq 100 en hausse de 2 %

OUVERTURE US : Les semi-conducteurs sont le moteur de la reprise

Action Airbus : essais en vol de nouvelles ailes
"Ce contenu est une communication marketing au sens de l'art. 24, paragraphe 3, de la directive 2014/65 /UE du Parlement européen et du Conseil du 15 mai 2014 concernant les marchés d'instruments financiers et modifiant la directive 2002/92 /CE et la directive 2011/61 /UE (MiFID II). La communication marketing n'est pas une recommandation d'investissement ou une information recommandant ou suggérant une stratégie d'investissement au sens du règlement (UE) n°596/2014 du Parlement européen et du Conseil du 16 avril 2014 sur les abus de marché (règlement sur les abus de marché) et abrogeant la directive 2003/6 / CE du Parlement européen et du Conseil et directives 2003/124 / CE, 2003/125 / CE et 2004/72 / CE de la Commission et règlement délégué (UE) 2016/958 de la Commission du 9 mars 2016 complétant le règlement (UE) n°596/2014 du Parlement européen et du Conseil en ce qui concerne les normes techniques de réglementation relatives aux modalités techniques de présentation objective de recommandations d'investissement ou d'autres informations recommandant ou suggérant une stratégie d'investissement et pour la divulgation d'intérêts particuliers ou d'indications de conflits d'intérêt ou tout autre conseil, y compris dans le domaine du conseil en investissement, au sens de l'article L321-1 du Code monétaire et financier. L’ensemble des informations, analyses et formations dispensées sont fournies à titre indicatif et ne doivent pas être interprétées comme un conseil, une recommandation, une sollicitation d’investissement ou incitation à acheter ou vendre des produits financiers. XTB ne peut être tenu responsable de l’utilisation qui en est faite et des conséquences qui en résultent, l’investisseur final restant le seul décisionnaire quant à la prise de position sur son compte de trading XTB. Toute utilisation des informations évoquées, et à cet égard toute décision prise relativement à une éventuelle opération d’achat ou de vente de CFD, est sous la responsabilité exclusive de l’investisseur final. Il est strictement interdit de reproduire ou de distribuer tout ou partie de ces informations à des fins commerciales ou privées. Les performances passées ne sont pas nécessairement indicatives des résultats futurs, et toute personne agissant sur la base de ces informations le fait entièrement à ses risques et périls. Les CFD sont des instruments complexes et présentent un risque élevé de perte rapide en capital en raison de l'effet de levier. 74% de comptes d'investisseurs de détail perdent de l'argent lors de la négociation de CFD avec ce fournisseur. Vous devez vous assurer que vous comprenez comment les CFD fonctionnent et que vous pouvez vous permettre de prendre le risque probable de perdre votre argent. Avec le Compte Risque Limité, le risque de pertes est limité au capital investi."